Samuel F. Fay1*, David S. Fay2§*, and Vikram E. Chhatre1,2
1Wyoming INBRE Bioinformatics Core
2Department of Molecular Biology, University of Wyoming, Laramie, WY USA
§Correspondence to: David S. Fay (davidfay@uwyo.edu)
* Authors have equal contribution
Abstract
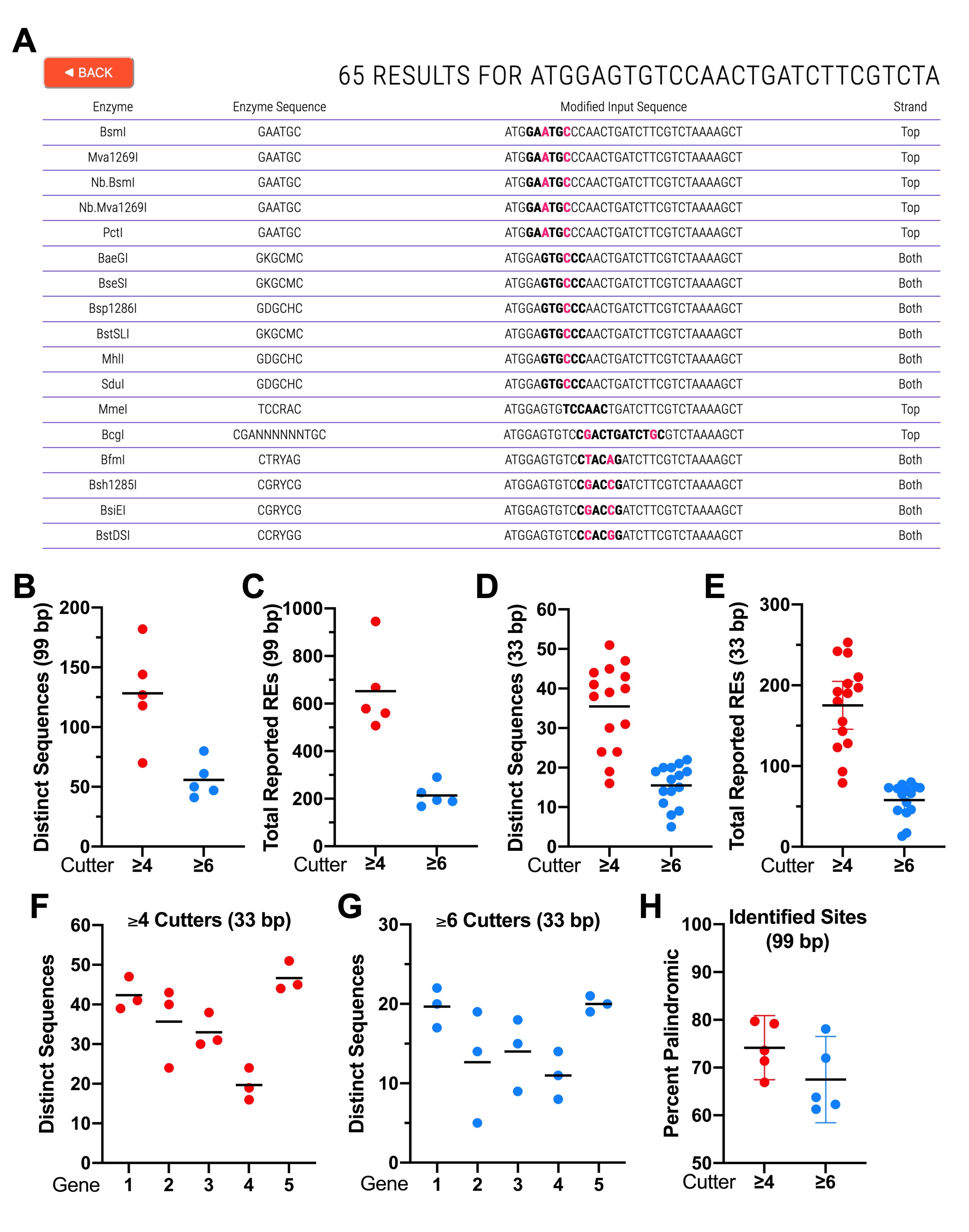
Description
Methods
Extended Data
- Description: CRISPRcruncher is a computational tool that analyzes an input coding sequence and produces a complete list of all possible changes that could be made that will create new RE sites while preserving the original peptide sequence.. Resource Type: Software. DOI: 10.22002/D1.1861
- Description: Extended data of RE sites identified by CRISPRcruncher, a computational tool that analyzes an input coding sequence and produces a complete list of all possible changes that could be made that will create new RE sites while preserving the original peptide sequence.. Resource Type: Dataset. DOI: 10.22002/D1.1862
Acknowledgements
Funding
Author Contributions
- Samuel F. Fay: Investigation, Methodology, Validation, Software, Resources, Formal analysis
- David S. Fay: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Validation, Visualization, Writing - original draft
- Vikram E. Chhatre: Conceptualization, Writing - review and editing, Methodology, Project administration, Supervision, Data curation
Reviewed By
Anonymous
Database Reference ID: WBPaper00060782
History
- Received: 12/5/2020
- Revision Received: 1/8/2021
- Accepted: 1/12/2021
- Published: 1/18/2021
Copyright
© 2021 by the authors. This is an open-access article distributed under the terms of the Creative Commons Attribution 4.0 International (CC BY 4.0) License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation
PubMed Central: PMC7816087
PubMed: 33490886
Cited By
microPublication Biology is published by
1200 E. California Blvd. MC 1-43 Pasadena, CA 91125
The microPublication project is supported by

The National Institute of Health -- Grant #: 1U01LM012672-01